How We Taught Our Platform to Understand RTOS Firmware


Why RTOS Analysis Matters (and Hurts)
RTOS are everywhere, yet almost no one can see inside them. Our customers often tell us that analyzing firmware built on real-time operating systems (RTOS) is one of the hardest tasks they face. Compared to Linux-based counterparts, these systems remain stubborn black boxes. Without deep and specialized knowledge, it is nearly impossible to perform meaningful analysis, which leaves most security teams struggling to even get started.
Safety-Critical, Long-Lived, and Locked Down
Customers working in automotive, medical devices, industrial control, and telecommunications all describe the same situation. RTOS are everywhere in these industries, and the devices that run them tend to stay in the field much longer than consumer electronics. That extended lifespan makes them sensitive targets for vulnerabilities that linger over time. Yet firmware access is tightly restricted. Vendors may only provide updates through locked-down customer portals, if they provide them at all. Even manufacturers have limited visibility: the RTOS they use is typically inherited from the SoC vendor, bundled with TCP/IP stacks and cryptographic libraries. Support often ends with the commercial lifespan of the chip, leaving customers unsure of what components and versions they are actually deploying.
Vulnerabilities Hiding in Plain Sight
When customers do manage to peek inside, the risks are clear. Over the last few years, researchers have uncovered critical flaws across widely deployed RTOS and their bundled libraries. Ripple20, a set of 19 vulnerabilities in Treck’s TCP/IP stack. Urgent 11, a collection of vulnerabilities in VxWorks disclosed by Armis. Issues in Realtek and Broadcom’s eCos SDKs that impacted telecommunications infrastructure. And a series of flaws reported by 0xdea across Zephyr, ThreadX, RIOT OS, and RT-Thread OS. Each of these examples confirms what our customers already know: this software is deeply embedded, widely deployed, and nearly impossible to inspect.
What Exactly is an RTOS?
Real-time operating systems (RTOS) are designed for one job above all else: predictability. Where general-purpose operating systems like Linux or Windows focus on fairness, throughput, and versatility, an RTOS is built to make sure tasks complete within strict timing guarantees. A missed deadline in an RTOS is not just a performance hiccup; in safety-critical contexts it can mean a car braking too late, a medical device misfiring, or a network packet dropped at exactly the wrong moment.
This design philosophy brings unique traits. RTOS kernels are small and optimized for determinism. They usually provide priority-based schedulers, lightweight memory management, and specialized drivers. On top of that, most SoC vendors ship their own customizations, from proprietary TCP/IP stacks to bundled cryptographic libraries. This makes every RTOS ecosystem look slightly different, even when based on the same core.
For security analysts, these traits quickly turn into roadblocks. The stripped-down kernel means fewer markers for identifying architecture and load addresses in a raw binary. Vendor modifications mean function signatures can drift from standard references. The long device lifespans and limited update mechanisms mean that whatever is deployed in the field is likely to stay there, flaws and all. In short: the very features that make RTOS so reliable in real time also make them uniquely hard to reverse engineer and secure.
Architecture Detection: Teaching Machines to Read Raw Binaries
If you want to understand binary code, you first need to disassemble and decompile it. But to do that, you must know the target architecture the code was built for. Think of it like using Google Translate: if you feed a Spanish text but tell the tool it’s German, the English output will be complete nonsense. The same is true for machine code: the wrong architecture produces garbage.
When working with executable file formats such as ELF, Mach-O, or PE, this information is conveniently stored in file metadata. That is how your favorite disassembler knows what to do. With raw binary files, however, there is no metadata. Just raw bytes. And that makes architecture detection much harder.
Existing Techniques
Over the years, researchers and practitioners have developed several ways to guess the architecture of raw binaries:
- Trial and Error. If you know the CPU or SoC, you can make an educated guess about the architecture and try variations until you get useful results. A higher number of valid functions identified by the decompiler usually means you’re on the right track.
- Prologue/Epilogue Matching. Compilers automatically inject short sequences at the start and end of functions to set up and tear down stack space. These predictable byte patterns can be matched against known prologues or epilogues for a given architecture. For example, binwalk’s "-A" option uses these signatures to identify architecture.
- Brute Forcing. Another approach is to loop over a list of architectures and attempt to decode the binary using each one. The architecture that yields the most valid instructions is likely correct. This is what binwalk’s
-Yoption does, leveraging Capstone as the disassembly backend. - Machine Learning. For nearly a decade, researchers have experimented with ML models to identify architectures automatically, using statistical features from the binary itself.
The Constraints We Faced
For our customers, architecture detection cannot be slow or manual. They upload a firmware image and expect fast, high-quality results with no manual review. That meant our solution had to deliver:
- High accuracy across many architectures, including rare ones.
- Speed fast enough to analyze multi-megabyte firmware in seconds.
- Full automation, since customers rarely know the underlying SoC details.
These requirements ruled out brute-force guessing or statistical models that take minutes to run. Instead, we focused on building a machine learning pipeline tuned for automation and speed.
From Markov Chains to Fingerprints
Several approaches inspired our work. Airbus released cpu-rec in 2017, a tool based on Markov chains and Kullback–Leibler distance. It uses the probability of byte sequences to distinguish architectures, since opcode encodings vary heavily across ISAs. While effective, it was too slow for large-scale analysis: processing a multi-megabyte binary could take several minutes.
Another key milestone was John Clemens’ paper Automatic Classification of Object Code Using Machine Learning (2018), which explored feature extraction from binaries and tested different models. Clemens built on the insight that each architecture has a unique “byte histogram fingerprint.”
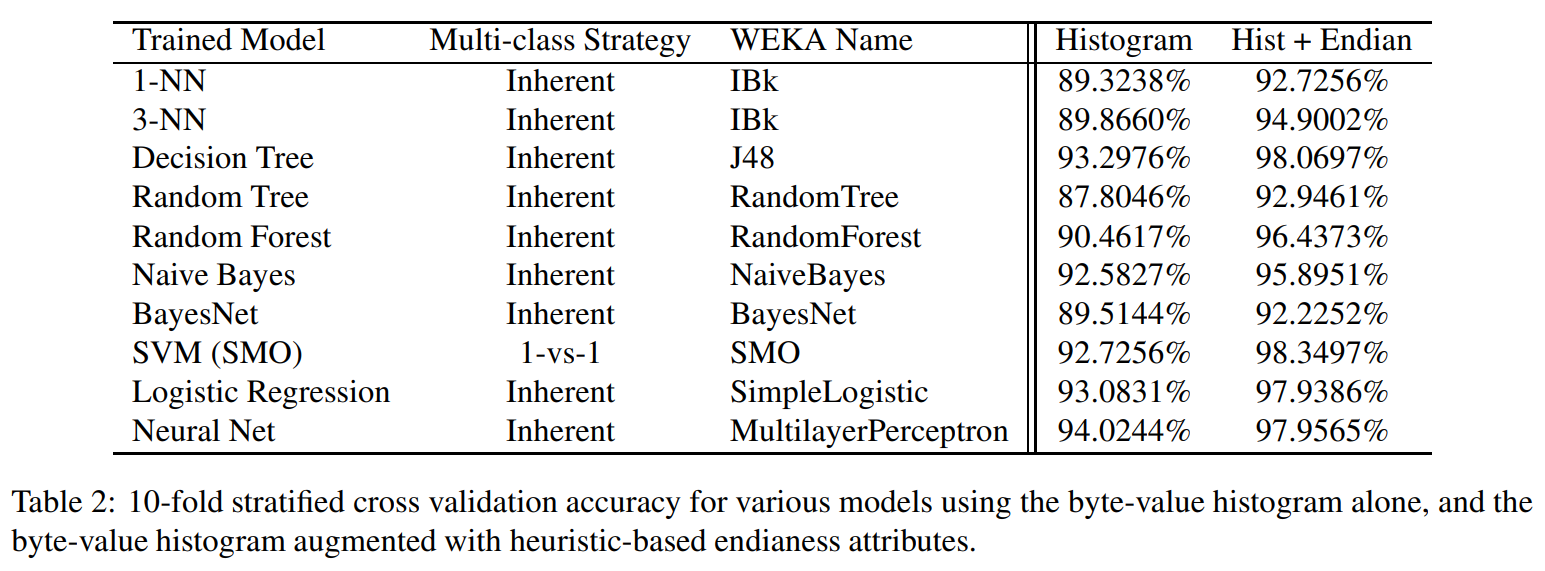
This idea was also beautifully illustrated in the PoC||GTFO 21 article Windrose Fingerprinting of Code Architecture, which showed how opcode frequency distributions can serve as distinctive signatures.
Our Approach
Building on these foundations, we designed a machine learning pipeline that balances accuracy, speed, and coverage.
Dataset. We compiled several open-source projects across architectures. These were chosen for diversity of code patterns and ease of cross-compilation. In total, we generated over 6,000 binaries, producing 1.3 GB of raw training data covering a total of 21 architecture combinations.
Hyperparameters. We ran a Bayesian hyperparameter search with cross-validation to tune the MLP.
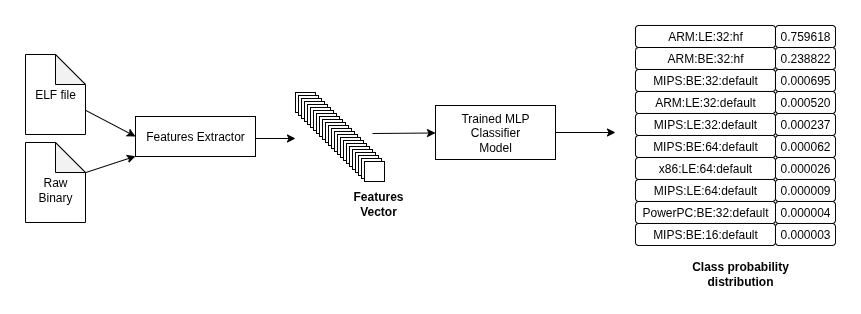
Architecture Detection: Results & Lessons Learned
Our classifier achieves 99.1% accuracy on the training set and 95.8% accuracy on the test set. In practice, this level of performance is well above the threshold required for automated analysis at scale. By comparison, traditional brute-force heuristics or statistical models like Markov chains often require minutes to run and still fall short in accuracy, especially on large binaries.
Most misclassifications fall into two categories: endianness mismatches or bit width confusion within MIPS. The latter was already documented by Clemens and remains a known challenge due to how instruction encodings overlap.
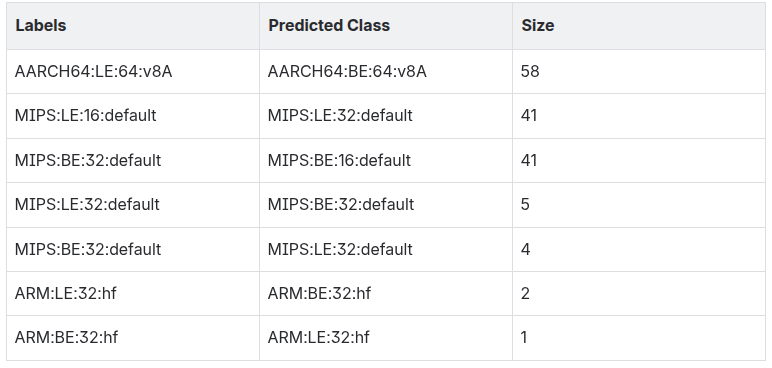
Despite these edge cases, the model consistently delivers above 95% accuracy, enabling reliable classification without manual intervention.
We continue to refine the model as new edge cases appear. For example, bare-metal firmware often mixes instruction lengths (ARM ↔︎ Thumb, MIPS32 ↔︎ MIPS16) to save space. By incorporating such samples into training, we’ve improved the model’s ability to correctly classify these challenging binaries. Over time, this incremental retraining will only strengthen the accuracy and resilience of the classifier.
For customers, this means confidence that disassembly results are correct from the very first step, without guesswork or manual fixing.
Load Address Detection: Finding the Right Place in Memory
Correctly identifying the load address of a binary is a fundamental requirement for meaningful firmware analysis. If you load a binary at the wrong address, cross-references between functions and data will not line up, leaving the disassembler output effectively useless.
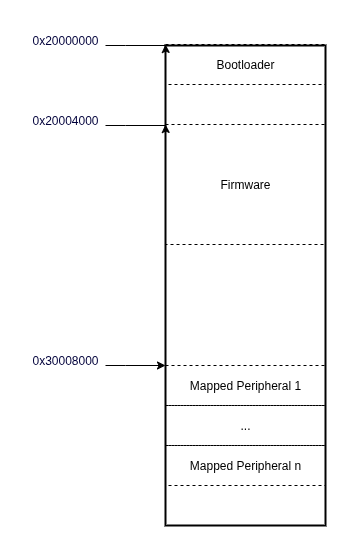
Every bare-metal firmware image is designed to live at a specific memory address. When you power on a device, the bootROM copies the bootloader into memory at a fixed address and transfers control. The bootloader does the same for the RTOS or Linux kernel image. Compilers and linkers bake these assumptions into the binary itself, so all code and data references are calculated relative to that starting offset. Getting the load address wrong means getting the entire analysis wrong.
Traditional Approaches
Over the years, researchers have created tools to recover load addresses from raw binaries. Most rely on the same principle:
- Collect the set of file offsets where strings are stored.
- Interpret aligned file offsets as potential pointers.
- Try different base addresses and measure how well string offsets overlap with pointer values.
- Pick the base address that produces the largest overlap.
Tools like basefind, basefind2, basefind.cpp, and rbasefind all implement this algorithm, but they are limited to 32-bit address spaces and scale poorly as binary size increases.
One exception is allyourbase, which reframes the overlap problem as a cross-correlation between indicator vectors. By using Fourier transforms and modular arithmetic, it sidesteps the brute-force search. This makes the algorithm pointer-length agnostic and much faster — but still impractical for very large address spaces.
Our Constraints and Approach
For our customers, load address detection needs to be fast, accurate, and completely automated. Whether the firmware is 10 MB or 1 GB, results must be delivered quickly, without manual intervention.
To meet those requirements, we implemented a pointer-length agnostic solution that limits the number of strings and pointers collected, ensuring consistent performance regardless of file size. Architecture detection also plays a key role: once we know the bit width and endianness, we only need to try one combination. In fact, load address detection doubles as a heuristic to validate architecture detection. If no valid address is found using the predicted endianness, but a valid one appears when flipping it, we can automatically correct the earlier classification.
Platform-Specific Heuristics
Beyond the generic approach, we also exploit architecture-specific shortcuts. For ARM binaries, we parse the reset vector table and collect page-aligned pointers, selecting the most frequent candidate as the load address. We then disassemble the reset handler; if the output matches expected instruction patterns, we know we have a valid result. Similarly, some firmware formats include explicit metadata about load addresses (e.g. ESP-IDF), which we parse directly when available.
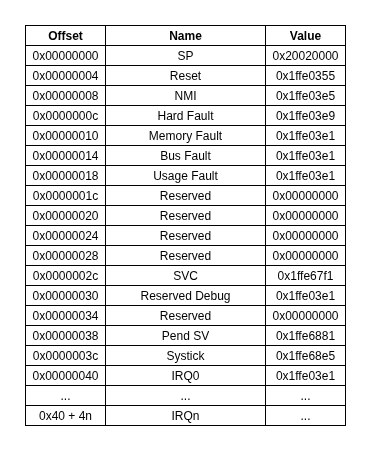
These heuristics reduce computation and boost accuracy by leveraging knowledge of specific platforms. Combined with our automated pipeline, they ensure that load address detection works seamlessly at scale, setting the stage for all subsequent analysis steps.
Component Detection: Identifying What’s Really Inside
On Linux firmware, our platform leverages a wide set of automated techniques to detect components. We can parse filenames, extract and analyze strings, use symbols when available, emulate code in an intermediate language, and apply custom version mappers. Together, these approaches provide reliable visibility into which libraries are present and which versions are in use.
In RTOS firmware, the situation is very different. Strings are limited, version information is rarely embedded, and symbols are typically absent (with VxWorks being a notable exception that we will cover in a future blog post). As a result, the same techniques that work so well on Linux, Android, or QNX provide little or no traction here.
Thanks to architecture detection and load address recovery, we can now load a raw RTOS binary into a disassembler with confidence. But that still leaves the most important question unanswered: what’s actually inside? Which RTOS kernel? Which TCP/IP stack? Which cryptographic library? And ideally, which version?
Function Signature Matching
To answer that, we turned to function signature matching. The process works like this:
- Disassemble and decompile the firmware.
- Identify all functions and generate a feature vector from each function’s intermediate representation.
- Compare these signatures against a database of known functions, each linked to a specific component and version.
If a function in the firmware resembles a known signature, we have a candidate match. By aggregating candidates across the binary, we can infer not just which components are present, but also their likely versions.
Building the Database
Of course, this required us to build a massive function signature database. We compiled every version of each component we wanted to support, across every architecture, using multiple compilers and flag combinations. Each open-source project comes with its own build quirks: some toggle features like preemptive scheduling, while others define constants such as maximum priority values or stack sizes. All of these can alter function signatures in subtle but significant ways.
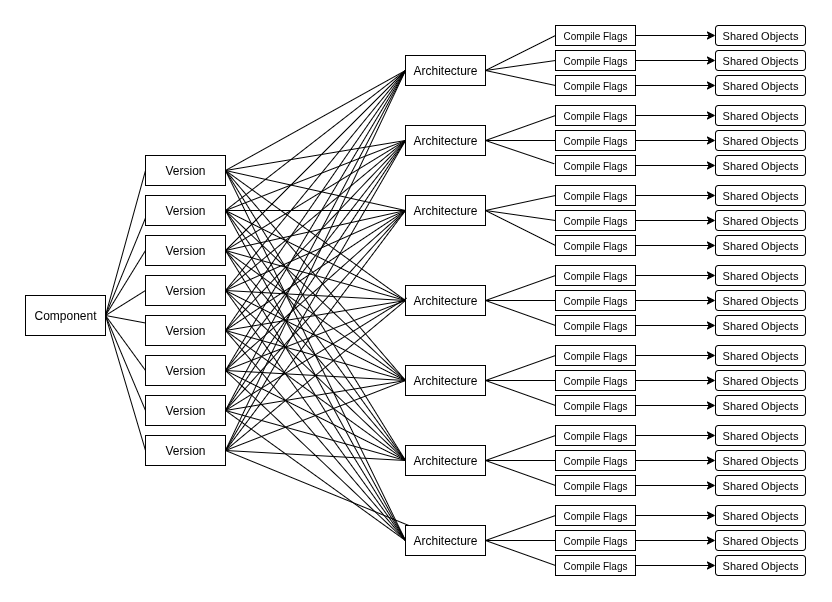
The combinations explode quickly: architectures × compilers × versions × flags. To keep this under control, we applied clustering analysis to identify which flags actually impact the generated function signatures. Flags with no effect were discarded, reducing both storage and processing needs while preserving accuracy. We repeated this process at both the compiler level (general flags) and the project level (feature-specific flags).
For closed source components, the pipeline can ingest prebuilt shared objects provided by vendors in their SDKs.
From Candidates to Components
Once a binary has been processed, every function is matched against the database to produce a set of candidates. These candidates then go through post-processing: grouping, clustering, and refinement based on matching attributes. The end result is a list of detected components with either an exact version or a narrowed version range when adjacent revisions are nearly identical. For example, distinguishing between 1.2.1 and 1.2.2 may not always be possible, but the correct version family can still be identified with high confidence.
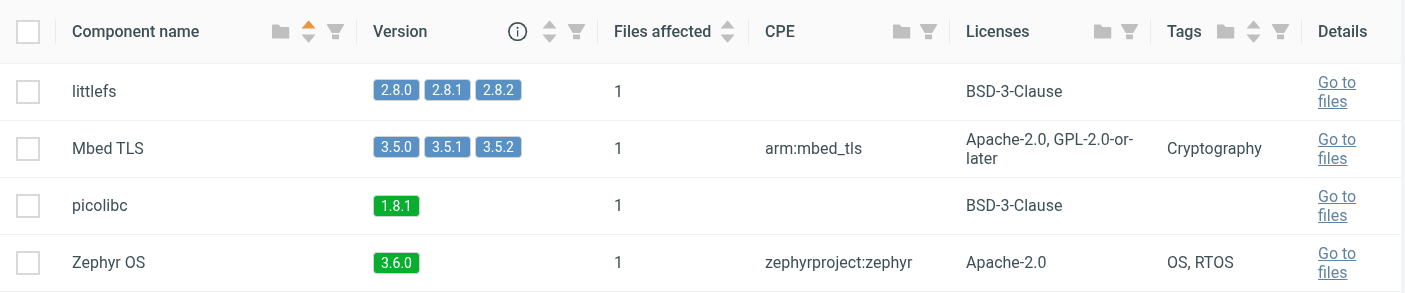
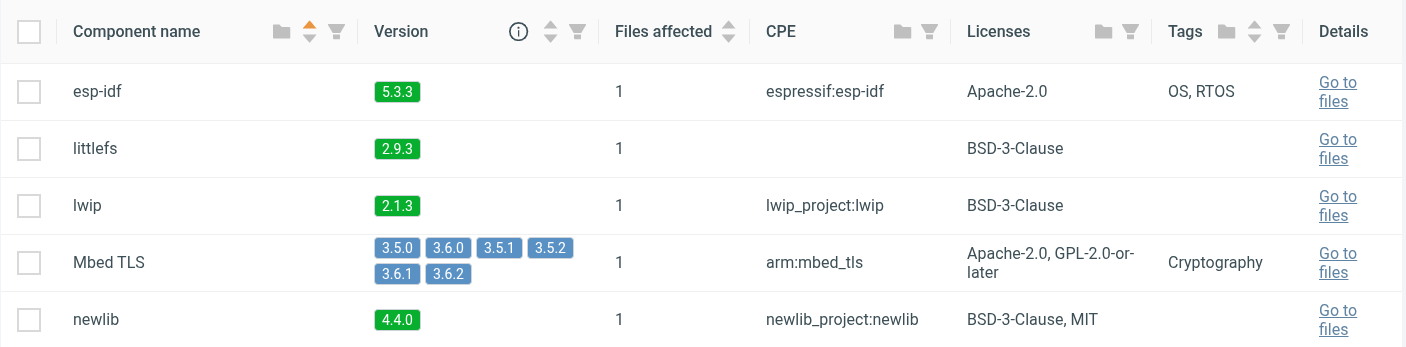
Supported Components
With this approach, we currently support automated detection of a broad set of RTOS kernels and libraries:
- RTOS Kernels: eCOS, FreeRTOS, ThreadX, µC/OS-II, µC/OS-III, Zephyr
- Cryptographic Libraries: mbedTLS, OpenSSL, PolarSSL, wolfSSL
- Standard Libraries: musl, newlib, picolibc
- TCP/IP Libraries: lwIP, PicoTCP, µIP
- File System Libraries: LittleFS
- Protocol Libraries: FreeRTOS coreHTTP, FreeRTOS coreMQTT
Of course, our team is continuously working on expanding this list by adding new components. You can find an up-to-date list in the platform documentation.
This pipeline gives our customers something they could not achieve before: a clear, automated inventory of the components inside RTOS firmware, even when vendors provide no documentation, symbols, or version information.
Conclusion and Key Takeaways
Real-time operating systems have long been a blind spot in firmware security analysis. Unlike Linux-based firmware, they rarely provide symbols, strings, or version information, making traditional techniques ineffective. Combined with their use in safety-critical industries and their long deployment lifespans, this opacity has left customers struggling to understand what is really running on their devices.
Over the past year, we tackled this challenge head-on. By developing automated methods for architecture detection, load address recovery, and component detection, we created a pipeline that can transform an opaque RTOS firmware image into a structured, analyzable view. Our machine learning–based architecture classifier achieves over 95% accuracy, load address detection runs quickly and at scale, and function signature matching now makes it possible to identify kernels, libraries, and even versions across a wide range of RTOS ecosystems.
The impact for customers is clear:
- Automated visibility into RTOS firmware that was previously treated as a black box.
- Reliable identification of embedded components, versions, and functions without manual review.
- A foundation for deeper security analysis, from task enumeration to automated impact assessment of vulnerabilities.
This is just the beginning. We plan to expand the catalog of supported RTOS and libraries, refine detection accuracy, and leverage our function-level insights for advanced tooling such as thread analysis and RTOS-specific vulnerability checks. The long-term goal is simple: make RTOS firmware as transparent and analyzable as Linux firmware already is.
For our customers, this means turning a once intractable problem into an automated, reliable step in their security workflow and finally bringing real-time operating systems out of the black box.
Über Onekey
ONEKEY ist der führende europäische Spezialist für Product Cybersecurity & Compliance Management und Teil des Anlageportfolios von PricewaterhouseCoopers Deutschland (PwC). Die einzigartige Kombination der automatisierten ONEKEY Product Cybersecurity & Compliance Platform (OCP) mit Expertenwissen und Beratungsdiensten bietet schnelle und umfassende Analyse-, Support- und Verwaltungsfunktionen zur Verbesserung der Produktsicherheit und -konformität — vom Kauf über das Design, die Entwicklung, die Produktion bis hin zum Ende des Produktlebenszyklus.

KONTAKT:
Sara Fortmann
Senior Marketing Manager
sara.fortmann@onekey.com
euromarcom public relations GmbH
team@euromarcom.de
VERWANDTE FORSCHUNGSARTIKEL

Latest Developments in Unblob: New Formats, Smarter Extraction, and a More Hardened Release Pipeline
Discover what changed in unblob since release 25.11.25, including new firmware and filesystem format support, smarter extraction workflows, robustness fixes, performance improvements, and stronger release security.

Security Advisory: Remote Code Execution on Viasat Modems (CVE-2024-6199)
Explore ONEKEY Research Lab's security advisory detailing a critical vulnerability in Viasat modems. Learn about the risks and recommended actions.

Bereit zur automatisierung ihrer Cybersicherheit & Compliance?
Machen Sie Cybersicherheit und Compliance mit ONEKEY effizient und effektiv.